

Interested in knowing how to analyze video data using Hadoop?
That's exactly what we will answer here.
Data analytics is becoming very important for online businesses. We write about "Advantages in Business Automation Solutions" at DevTeamSpace's blog. There is so much data being generated every second, and so much potential to grow your business by understanding it.
But how do you even begin to process that much data? Luckily, there are some very smart people who have spent time thinking about this problem, and they've come up with some great tools. Today, I'm going to discuss how to analyze video data using Hadoop.
What is Hadoop?
Hadoop is an open-source framework created by Apache. It's designed for distributed storage and concurrent processing of big data sets. In other words, it's a technology built for dealing with huge amounts of data.

It does this with a clever programming idea called MapReduce, which allows processing to be done on thousands of servers at the same time. By doing this, you can solve problems quickly that would take you days or even weeks on a single computer.
Hadoop works with a 'cluster' of many computers or servers built from relatively cheap commodity hardware. All of these work together to solve very large processing problems.
Of course, when running lots of computers (especially for extended periods of time), you can expect things to go wrong. The beauty of the Hadoop framework is that failures are expected, and dealing with problems is a built-in functionality.
Hadoop for Video Data
If it is designed for massive amounts of data, why would you need to use Hadoop for video processing?
Imagine trying to teach a car how to drive with manual coding alone. The number of commands and instructions you would have to give the car for every possible scenario is in the billions, probably trillions.
That's completely unfeasible, even for big companies like Google and Uber, currently working with autonomous vehicles.
The way they do it is by processing thousands of hours of video with clever machine learning algorithms, and have the cars program themselves.
Also, video has become the biggest and most important type of content on the internet. People love watching videos, especially on sites like YouTube and Facebook. Check out this chart showing the insane growth in videos uploaded to YouTube over the last 10 years. 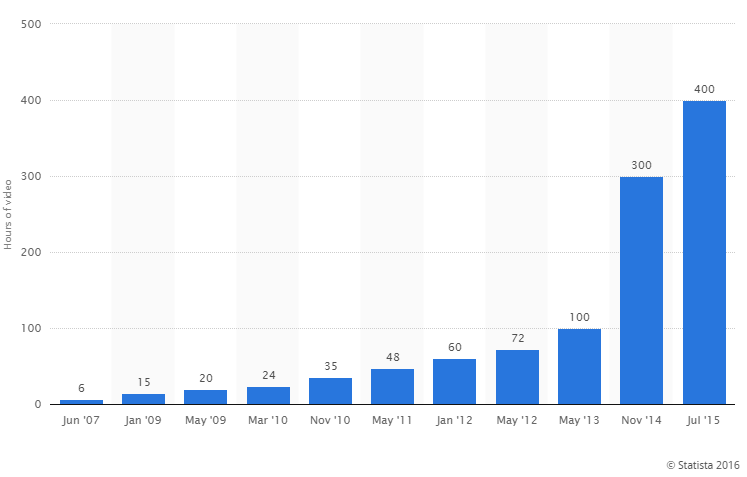
Combine this with the trend towards higher-quality video, and you have an awful lot of data being created and consumed.
Hidden within all those frames and pixels is valuable information about customers that businesses can use. Habits and trends can be used to spot gaps in the market and investment opportunities.
To uncover these insights, you first need a place to put all of that video data - and your computer probably isn't up to the task.
Distributed Storage
Large-scale video analytics on Hadoop requires analyzing large data sets - and you need somewhere to put them.
1,200 top developers
us since 2016
Rather than have one massive file system (like a supercomputer), Hadoop uses what's called a distributed file system. It spreads files across any number of devices so they can be accessed easily for processing. All device failures are handled automatically by the framework - so if any single part of the system crashes, it won't bring down the rest.
This is great for businesses, as cheap, off-the-shelf hardware can be used instead of expensive, specialized systems. If you need to ramp up your computing power, just add some more servers to your current system! No need to start over.
Concurrent Processing - MapReduce
Once you've got a distributed file system online and a data set ready to go, the next question is how to process video files with Hadoop
With a Hadoop system, this is done concurrently. That means each of the devices in the system will be performing tasks and processing data at the same time, independently of each other.
MapReduce is a part of the framework that coordinates all of this. It's responsible for reading the files from the distributed filesystem, scheduling tasks for all the concurrent devices, monitoring those tasks, and making sure any failed tasks are re-executed.
Don't worry, it's difficult to get your head around all this at first. Let's take a look at a real-world example.
Hadoop Video Processing Example
One example of where Hadoop is used is in video surveillance systems. Rather than maintaining expensive security teams to monitor endless hours of footage, a Hadoop video processing system can be used to sift through all the data automatically.
To actually achieve this, a security company would need to monitor large amounts of video data very quickly. Incidents or potential dangers need to be spotted in minutes or seconds, not days.
The surveillance could be delivered to a distributed file system in real time. Then, a Hadoop cluster would analyze it frame by frame, detecting any suspicious activity as quickly as possible.
Check out this page for a detailed description of how a system like this might work, including a distributed video transcoding system.
Main Benefits of Using Hadoop to analyze a video
Some of the biggest benefits of data analytics using Hadoop are:
- It's cheap - you can build a system from cheap and readily available parts, rather than specialist hardware.
- It's flexible - and allows you to adapt your system as your business needs change.
- It has a great open source community - there is a great community working on improving Hadoop all the time.
In fact, the open-source community and some commercial companies are working on tools that make Hadoop easier to use for businesses. These will make Hadoop more accessible to everyone.
The list of major companies using Hadoop is huge. Here's a quick sample of some of the biggest ones:
- Yahoo;
- Adobe;
- intel;
- Amazon;
- IBM;
- cloudera;
- MAPR;
- Databricks;
- bizo;
- Hortonworks;
- MANY more.
Final thoughts on how to analyze a video
We've looked at how to analyze video data using Hadoop, some reasons you might want to, and example applications. Whether or not Hadoop is the right framework for your application is a difficult question. It all depends on the type of data you have and the type of processing you need to do.
If a distributed file system and a large-scale concurrent programming framework are what you need, then Hadoop is a great framework to work with.
Data analytics using Hadoop can get very complex. Only highly skilled developers will be able to extract the right information. The problem is that there is actually a shortage of developers who have these skills.
Rather than hiring or training a developer for your team, a good option is to consult with a team that already has experience with analyzing videos in Hadoop. DevTeam.Space can help you here via its field-expert software developers community.
Write to us your initial project specifications via this form, and one of our managers will get back to you to discuss further details on how we can help.
Further Reading
Here are a few articles that might also interest you:
- Why AI Development Tools Matter?
- How to hire Expert Big Data Developers?
- Drupal Security: How to Protect Your Website?
- DevTeam.Space Named to Clutch 1,000 Global Leaders List
Frequently Asked Questions on Analyzing a Video using Hadoop
First, you need to ensure that the video is digitized. Establish the frame rate and download a video analytics tool like Hadoop. Follow the steps and define the kind of analysis process that you desire, and the results will be in very quickly, and just what you want.
This is the process of a computer program breaking down the components of a video clip into various results. These can include anything from genre to the ratio of male to female screen time, etc.
Video analysis offers numerous benefits to an intended audience, such as better communication, analyzing trends, monitoring performance, etc.







